T2I Generation Results
(SD3)

“...sign that reads ‘Othello’.”

"A fire hydrant has some writing on its side."

"Knolling of a drawing tools."

"Ethereal fantasy concept art of thunder god with hammer."

"A yellow and green object with a brown bird on top of it."
Text Guided Image Editing Results
(SD3)

"stone building” → “wooden lighthouse"

“yellow building” → “red building, open door”

“car” → “motorcycle”

“green and white caterpillar” → “blue and yellow butterfly”

“rocky beach” → “sandy beach”
Abstract
While recent advancements in generative modeling have significantly improved text-image alignment, some residual misalignment between text and image representations still remains. Although many approaches have attempted to address this issue by fine-tuning models using various reward models, etc., we revisit the challenge from the perspective of representation alignment—an approach that has gained popularity with the success of REPresentation Alignment (REPA). We first argue that conventional text-to-image (T2I) diffusion models, typically trained on paired image and text data (i.e., positive pairs) by minimizing score matching or flow matching losses, is suboptimal from the standpoint of representation alignment. Instead, a better alignment can be achieved through contrastive learning that leverages both positive and negative pairs. To achieve this efficiently even with pretrained models, we introduce a lightweight contrastive fine-tuning strategy called SoftREPA that uses soft text tokens. This approach improves alignment with minimal computational overhead by adding fewer than 1M trainable parameters to the pretrained model. Our theoretical analysis demonstrates that our method explicitly increases the mutual information between text and image representations, leading to enhanced semantic consistency. Experimental results across text-to-image generation and text-guided image editing tasks validate the effectiveness of our approach in improving the semantic consistency of T2I generative models.
Method
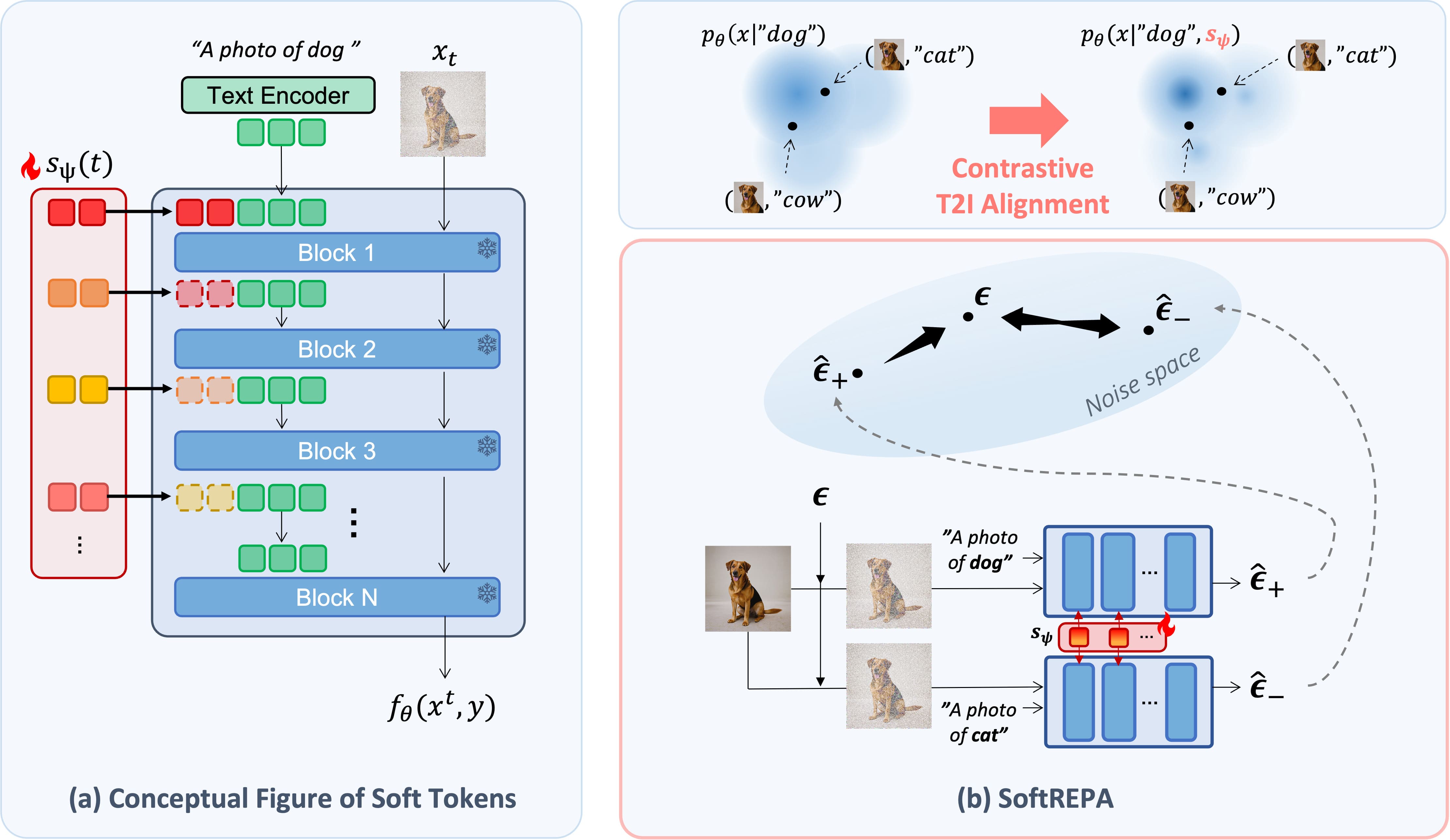
In SoftREPA, the soft tokens are optimized to contrastively match the score with positively conditioned predicted noise while repelling the score from negatively conditioned predicted noise. This process implicitly sharpens the joint probability distribution of images and text by reducing the log probability of negatively paired conditions. The learnable soft tokens are prepended to the text features across the upper layers, with each layer’s previous soft tokens being replaced by the soft tokens of the current layer.
Experimental Results
1. T2I Generation

| Model | ImageReward ↑ | CLIP ↑ | HPS ↑ | LPIPS ↓ |
|---|---|---|---|---|
| SD1.5 | 0.177 | 0.265 | 0.251 | 0.438 |
| SD1.5 + Ours | 0.274 | 0.271 | 0.252 | 0.437 |
| SDXL | 0.750 | 0.267 | 0.273 | 0.420 |
| SDXL + Ours | 0.852 | 0.268 | 0.283 | 0.423 |
| SD3 | 0.942 | 0.263 | 0.280 | 0.424 |
| SD3 + Ours | 1.085 | 0.269 | 0.289 | 0.428 |
We evaluate SoftREPA across diffusion and rectified flow models, and across UNet and Transformer architectures. Our approach consistently improves alignment and image quality on all fronts, demonstrating strong generalization.
2. Text Guided Image Editing

| Model | Dataset | ImageReward ↑ | CLIP ↑ | HPS ↑ | LPIPS ↓ |
|---|---|---|---|---|---|
| FlowEdit | DIV2K | 0.380 | 0.260 | 0.255 | 0.154 |
| FlowEdit + Ours | DIV2K | 0.466 | 0.263 | 0.260 | 0.149 |
| FlowEdit | Cat2Dog | 0.937 | 0.225 | 0.266 | 0.199 |
| FlowEdit + Ours | Cat2Dog | 1.111 | 0.226 | 0.269 | 0.173 |
SoftREPA boosts alignment and visual quality in editing tasks with fewer steps and lower CFG scale.
Key Contributions
- 📌 SoftREPA introduces soft tokens trained with contrastive learning.
- ⚡ Requires < 1M trainable parameters, minimal compute cost.
- 💡 Improves semantic representation alignment in generation and editing without model full finetuning.